(アニメの感想は、2016年5月当時の感想です)
未来日記の作者えすのサカエ氏の「ビッグオーダー」がアニメ放映中です。
男子高校生星宮エイジの世界を支配する能力で、九州で国を立ち上げ(なんと九州国という)、山口県へ攻め込んで、国盗り合戦?的な展開をしていく内容です。(今のところは)
主人公の歩いた場所が、支配できる場所になるのですが、日本を征服するために、47都道府県をすべて廻るのでしょうか。他の能力者を支配して、目的をこなすあたりが、コマンドラインと似てる気がします。(他の能力者=perlやら、rubyやら。無理やり感)
しかし残念ながらコマンドの達人になっても、コマンドラインで都道府県を征服することはできないかと思いますので、都道府県データの整理ぐらいで我慢しておきましょう。
「全国の村がつく住所の数をgrepとwcで求める」で、wgetした郵便番号データを使って、データ抽出をしてみます。
まずは、47都道府県の一覧を作成してみます。コマンドを見ると、ものすごく回りくどいことをしているように見えますね。nkfは3回も使われていますが、これには理由があります。
~$ nkf < KEN_ALL.CSV | awk -F\",\" '{print $6}' |
> uniq | nl -w3 -s. | nkf -s | pr -t3J | expand | nkf
1.北海道 17.石川県 33.岡山県
2.青森県 18.福井県 34.広島県
3.岩手県 19.山梨県 35.山口県
4.宮城県 20.長野県 36.徳島県
5.秋田県 21.岐阜県 37.香川県
6.山形県 22.静岡県 38.愛媛県
7.福島県 23.愛知県 39.高知県
8.茨城県 24.三重県 40.福岡県
9.栃木県 25.滋賀県 41.佐賀県
10.群馬県 26.京都府 42.長崎県
11.埼玉県 27.大阪府 43.熊本県
12.千葉県 28.兵庫県 44.大分県
13.東京都 29.奈良県 45.宮崎県
14.神奈川県 30.和歌山県 46.鹿児島県
15.新潟県 31.鳥取県 47.沖縄県
16.富山県 32.島根県
~$
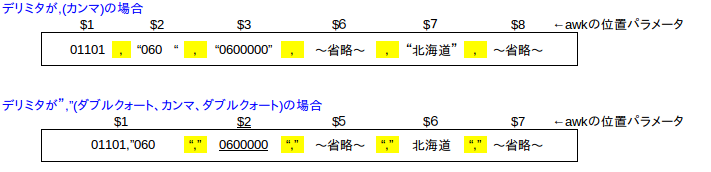
最初のnkf は、SJISからUTF8への変換です。それをawkへ渡していますが、オプション-Fに指定しているのが、デリミタです。
\”,\”は、単に、”,”の意味です。エスケープしないとbashでのダブルクォートと認識されてしまうためです。
デリミタをカンマとした場合は、位置パラメータの7番目に北海道という文字列が格納されますが、デリミタを変更して6番目になっているためprint $6としています。
uniqは、重複の削除です。uniqは通常はsortで並べ替えした状態で実行する必要がありますが、この郵便データはすでに並べ替えされていますので、sortコマンドを使用せずuniqのみ実行しています。
nkf -sでは、コマンドラインの先頭でせっかくnkfをかけたのに、またSJISに戻しています。どういうことでしょうか。nkfを一回だけ使うようにコマンドラインを組むと以下のような結果となります。
~$ nkf < KEN_ALL.CSV | awk -F\",\" '{print $6}' |
> uniq | nl -w3 -s. | pr -t3J | expand
1.北海道 17.石川県 33.岡山県
2.青森県 18.福井県 34.広島県
3.岩手県 19.山梨県 35.山口県
4.宮城県 20.長野県 36.徳島県
5.秋田県 21.岐阜県 37.香川県
6.山形県 22.静岡県 38.愛媛県
7.福島県 23.愛知県 39.高知県
8.茨城県 24.三重県 40.福岡県
9.栃木県 25.滋賀県 41.佐賀県
10.群馬県 26.京都府 42.長崎県
11.埼玉県 27.大阪府 43.熊本県
12.千葉県 28.兵庫県 44.大分県
13.東京都 29.奈良県 45.宮崎県
14.神奈川県 30.和歌山県 46.鹿児島県
15.新潟県 31.鳥取県 47.沖縄県
16.富山県 32.島根県
表示がずれました。
SJISの良いところは、全角を表すのに2文字固定になるところです。expand等、ASCIIにしか対応していないコマンドを使う場合は、一旦SJISにすることで、文字数の整合がとれて、見栄えがよくなります。
都道府県をナンバリングしているnlコマンドでは、番号の桁数を指定する-wオプションと、番号の後の文字列を指定する-sオプションを使っています。
最後にprで3列表示して、expandでタブをスペースに変換しています。
今度はuniqを使用せず、連想配列を使用して、重複データの削除をしましょう。大量に表示されてしまいますので、headしています。
まず重複データの削除をしない場合です。
perlでは-aオプションを使うことで、-Fで指定した文字列をデリミタとして$F[0]〜の配列に一行の各フィールドの文字列が格納されます。
~$ nkf < KEN_ALL.CSV | perl -F/\",\"/ -nae ' > $s = "$F[5] $F[6]";print $s ."\n"' | head 北海道 札幌市中央区 北海道 札幌市中央区 北海道 札幌市中央区 北海道 札幌市中央区 北海道 札幌市中央区 北海道 札幌市中央区 北海道 札幌市中央区 北海道 札幌市中央区 北海道 札幌市中央区 北海道 札幌市中央区 ~$
当然ですが、重複データが表示されています。
次に連想配列を使って重複データの削除をする場合です。
連想配列が何かというと、普通の配列が以下のように表現するなら、
a[0] = 1
a[2] = 10
以下のように文字列を添字として使える配列のことです。(配列でなく連想配列ですが)
a[“ABC”] = 5
a[“ドレミ”] = 20
言語によって、辞書と言ったりhashmapと言ったり様々です。
では使ってみます。
~$ nkf < KEN_ALL.CSV | perl -F/\",\"/ -nae '
> $s = "$F[5] $F[6]";if($hash{$s}++ == 0){print $s ."\n"}' | head
北海道 札幌市中央区
北海道 札幌市北区
北海道 札幌市東区
北海道 札幌市白石区
北海道 札幌市豊平区
北海道 札幌市南区
北海道 札幌市西区
北海道 札幌市厚別区
北海道 札幌市手稲区
北海道 札幌市清田区
~$
$hashという変数を連想配列として使っています。$hash{“北海道 札幌市中央区”} ++ とすることにより、カウントアップされ、一度カウントアップされた場合にその文字列を表示しないようにしています。


コメント